In this article, we are going to deploy AlwaysOn Availability Group on a production-grade three-node Microsoft SQL Server Cluster. Let’s start with understanding the architecture we will be using. The virtual machines’ details are as follows:
| Hostname | IP Address | OS | Role |
| cc-focal | 10.10.0.11 | Ubuntu 20.04 | Controller |
| mssql1 | 10.10.0.51 | Ubuntu 20.04 | Primary |
| mssql2 | 10.10.0.52 | Ubuntu 20.04 | Replica |
| mssql3 | 10.10.0.53 | Ubuntu 20.04 | Replica |
To start us off, we will update/etc/hosts in the ClusterControl node and all the participating nodes in the availability group.
The below screenshot shows an updated /etc/hosts on cc-focal (ClusterControl node):
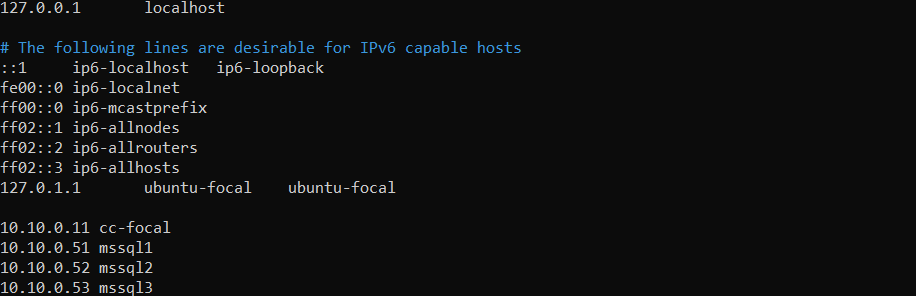
After updating the hosts file, log in to ClusterControl V2, and click the Create Service button, as shown below:

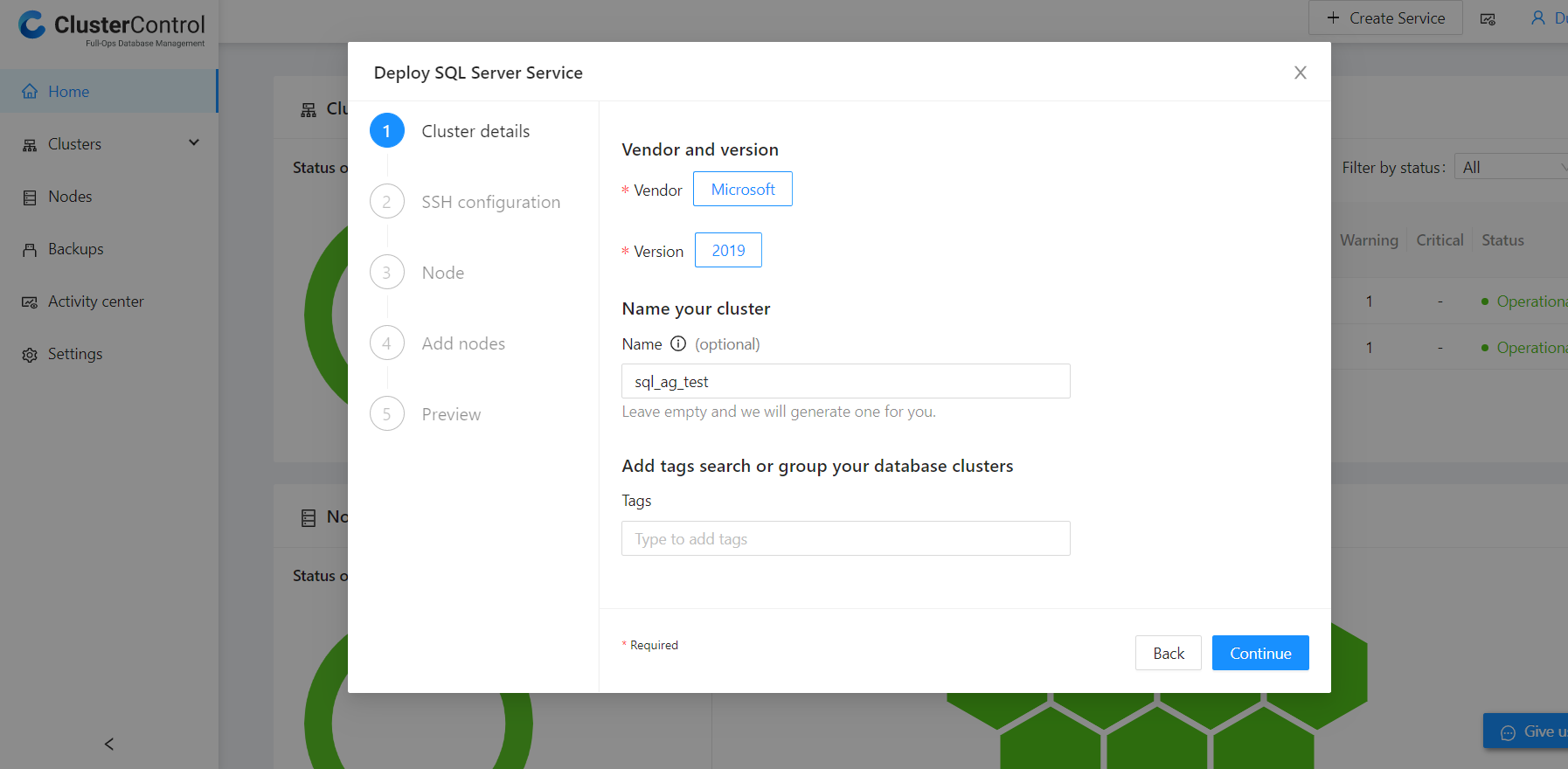
On the service launch wizard page, click on Create a database cluster, which directs to the deploy service page. Click on the SQL Server option. On the Deploy SQL Server Service page, you can name your cluster or let ClusterControl generate one for you. In this instance, the cluster name is “sql_ag_test” as shown in the image below:
ClusterControl directs to SSH Configuration. It’s worth noting that the SSH User should use passwordless sudo, which is highly recommended. In our scenario, “vagrant” user will be our SSH User, as shown in the image below:
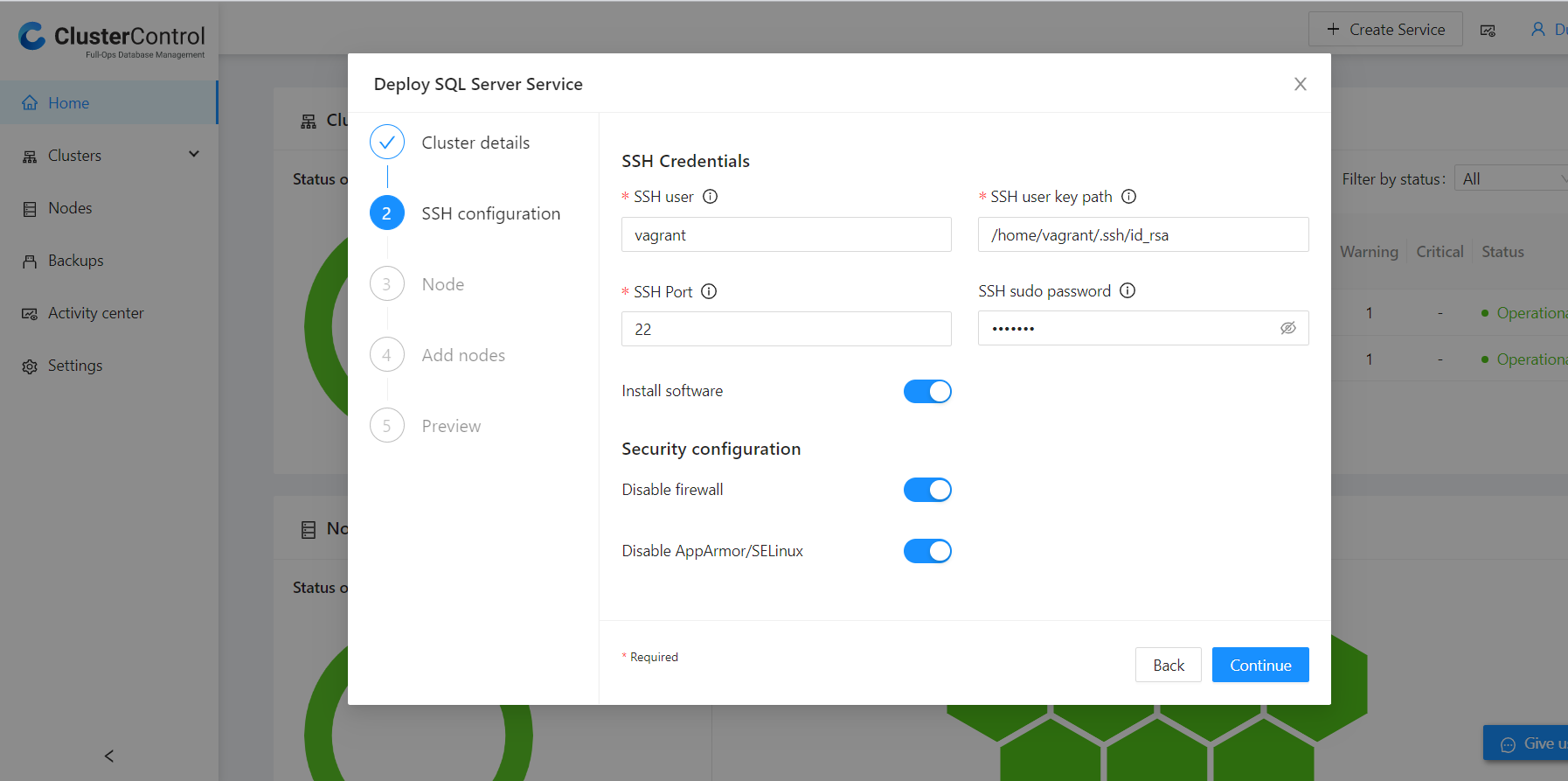
The position of the Install Software button will be dependent on whether your Microsoft SQL Server is already installed (standalone servers) or new.
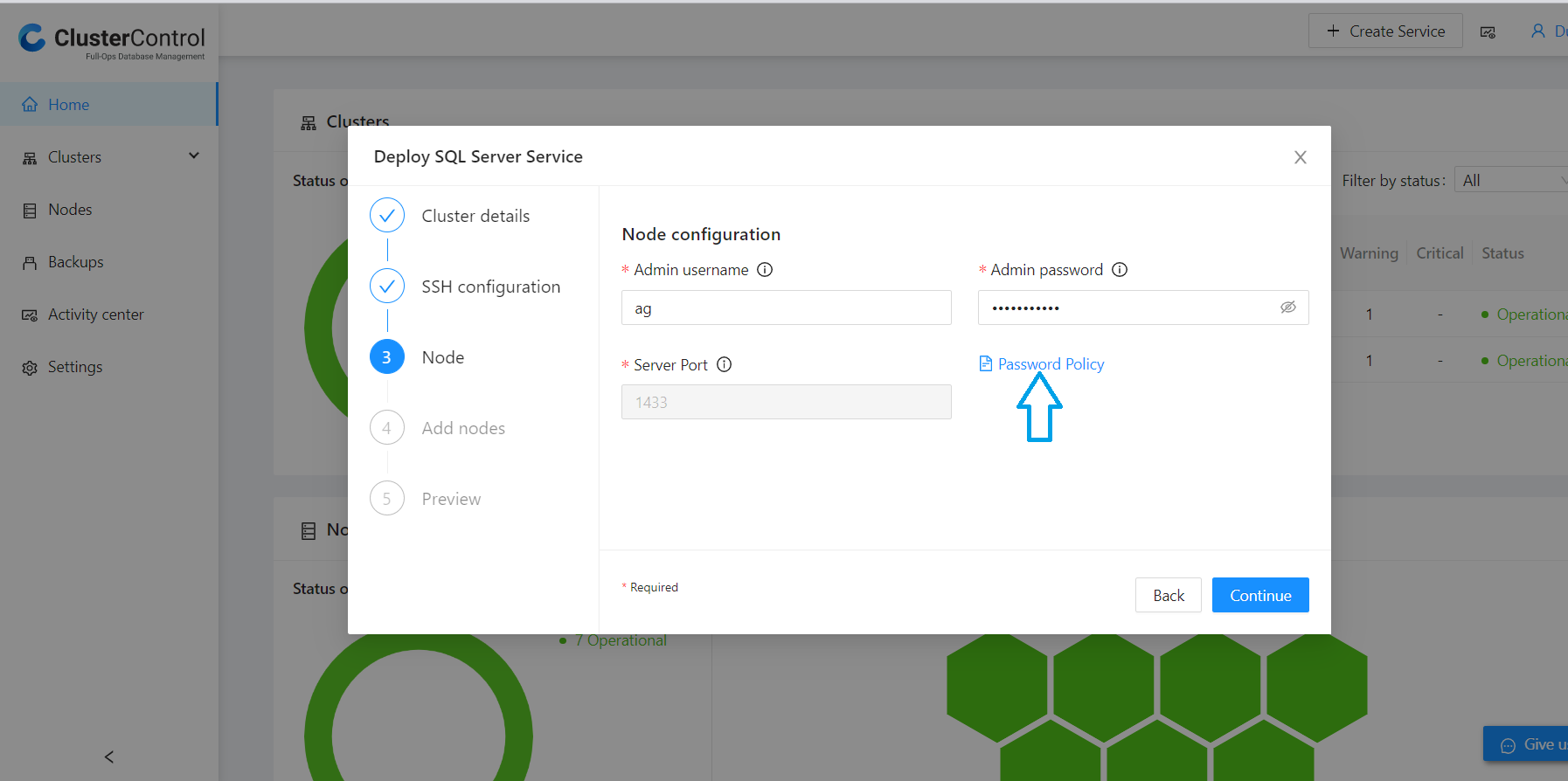
On the node configuration page, create an Admin Username and password as per the password policy link on the same page. As shown below:
The last configuration step is to add the nodes, and unlike the norm in ClusterControl of using the IP address, we use the hostnames of the nodes as shown below:
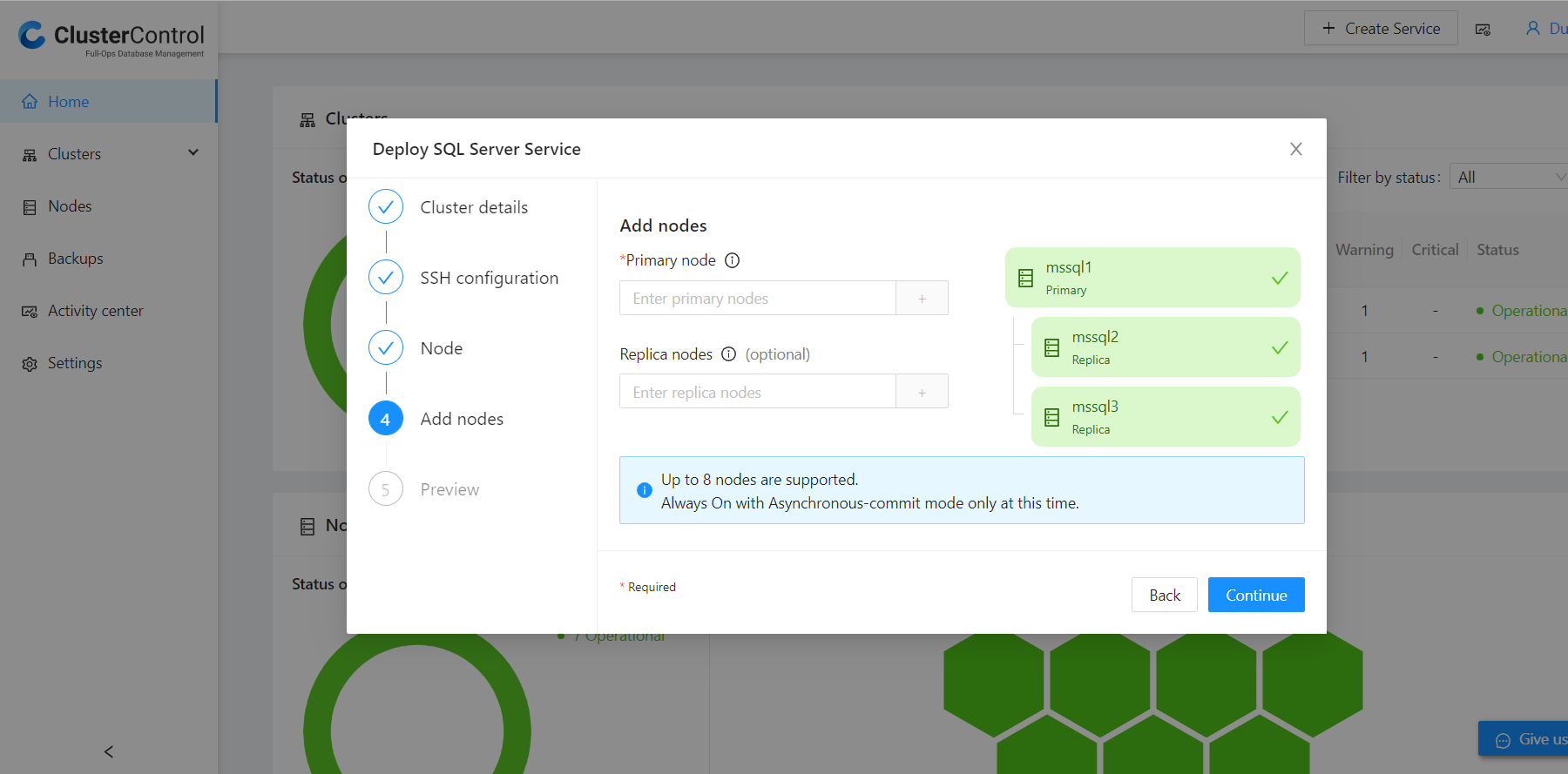
ClusterControl finally directs to the preview page, and the deployment process starts once the confirmation button is clicked. 
The activity list will show the process run log, which displays the action being executed and its status (success or fail). ClusterControl will:
- Install Microsoft SQL Server 2019
- Create a database cluster
- Enable AlwaysOn
- Create an authentication certificate on all nodes
- Create mirroring endpoints on all nodes
- Create an availability group.
Adding a database to the Availability Group
Initially, it is imperative to understand the prerequisites the databases should pass before adding them to the Availability Group:
- The database must have a FULL log backup.
- The database must be in the FULL recovery mode.
To create and backup a database called test1 on the Primary Microsoft SQL Server instance, run this T-SQL script:
CREATE DATABASE [test1];
ALTER DATABASE [test1] SET RECOVERY FULL;
BACKUP DATABASE [test1]
TO DISK = N'/var/opt/mssql/data/test1.bak';To add test1 to the Availability Group s9s_ag1 (the AG name is in the job log) on the same instance, run the following T-SQL script:
ALTER AVAILABILITY GROUP [s9s_ag1] ADD DATABASE [test1];To confirm that the test1 database has been created and synchronized on each secondary Microsoft SQL Server replica, run the following query on the replicas:
SELECT * FROM sys.databases WHERE name = 'test1';
GO
SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;